
Hi all, this is the second part of the project Speedy. If you want to see first part, please follow this link. In this session, we have a simple task to do, “Digit Extraction”. As you all know, we are able to detect traffic sign. But this is not enough for our project. We need to know what it is in the sign. To make it clearly understandable by computer, we will process each digit individually. Let’s start to work. Chap Chap!
###
# /main.py
###
image = cv2.imread("../../images/speed-7.jpg", 1)
mask, circles, rois = tslsr.tslsr(image)With the help of tslsr function, we can detect the traffic speed limit signs easily. So we will start by doing it first. You can find the details about this process in part1. Now, you can see the essential part of digit extraction in the code below.
###
# /main.py
###
digits = tslsr.extractDigits(roi)
plt.figure(3)
for i in range(len(digits)):
p = int("1" + str(len(digits)) + "" + str(i + 1))
plt.subplot(p)
plt.imshow(digits[i])If you send the ‘roi’ that we got from tslsr function, then you will get each digits(contours) as an element of a list.
Let’s look at the details of extractDigits function.
###
# /tslsr/tslsr.py
###
def extractDigits(roi):
mroi, rects = __bound_contours(roi)
digits = []
for (x, y, w, h) in utils.eliminate_child_rects(rects):
digits.append(roi[y : y + h, x : x + w])
return digitsAs you can see, we are finding the contours of the image and creating the bounding rectangles for these contours. After all of this, we need to eliminate unwanted rectangles, so I wrote a function to prevent the cases like in the picture below.

In this case we have two nested rectangles and this is not the thing that we want to see. So we need to get rid of the inner rectangle.
In the eliminate_child_rects function of the utils module, we will remove all the child and similar rectangles from the list. You can see the details of the function below.
###
# /tslsr/utils.py
###
def eliminate_child_rects(rects):
rectDict = dict()
newRects = []
rects = list(set(rects))
for i in range(len(rects)):
r1 = rects[i]
for j in range(len(rects)):
r2 = rects[j]
if is_same_rectangle(r1, r2):
print("R1:",r1, "R2:", r2, " same!")
continue
if is_contains_rectangle(rects[i], rects[j]):
print(rects[i], "contains", rects[j])
if i not in rectDict:
rectDict[i] = [rects[j]]
else:
rectDict[i].append(rects[j])
elif is_similar_rectangle(r1, r2, 5):
print(r1, "is similar to", r2)
eliminatedR = None
if get_bigger_rect(r1, r2) == r1:
index = i
eliminatedR = r2
else:
index = j
eliminatedR = r1
print("index:", i, "eliminatedR:", eliminatedR)
if index not in rectDict:
rectDict[index] = [eliminatedR]
else:
rectDict[index].append(eliminatedR)
for (k, v) in rectDict.items():
for r in v:
if r in rects:
rects.remove(r)
for r in rects:
newRects.append(r)
return newRectsI know you want to see the result of this part and I will show you :)
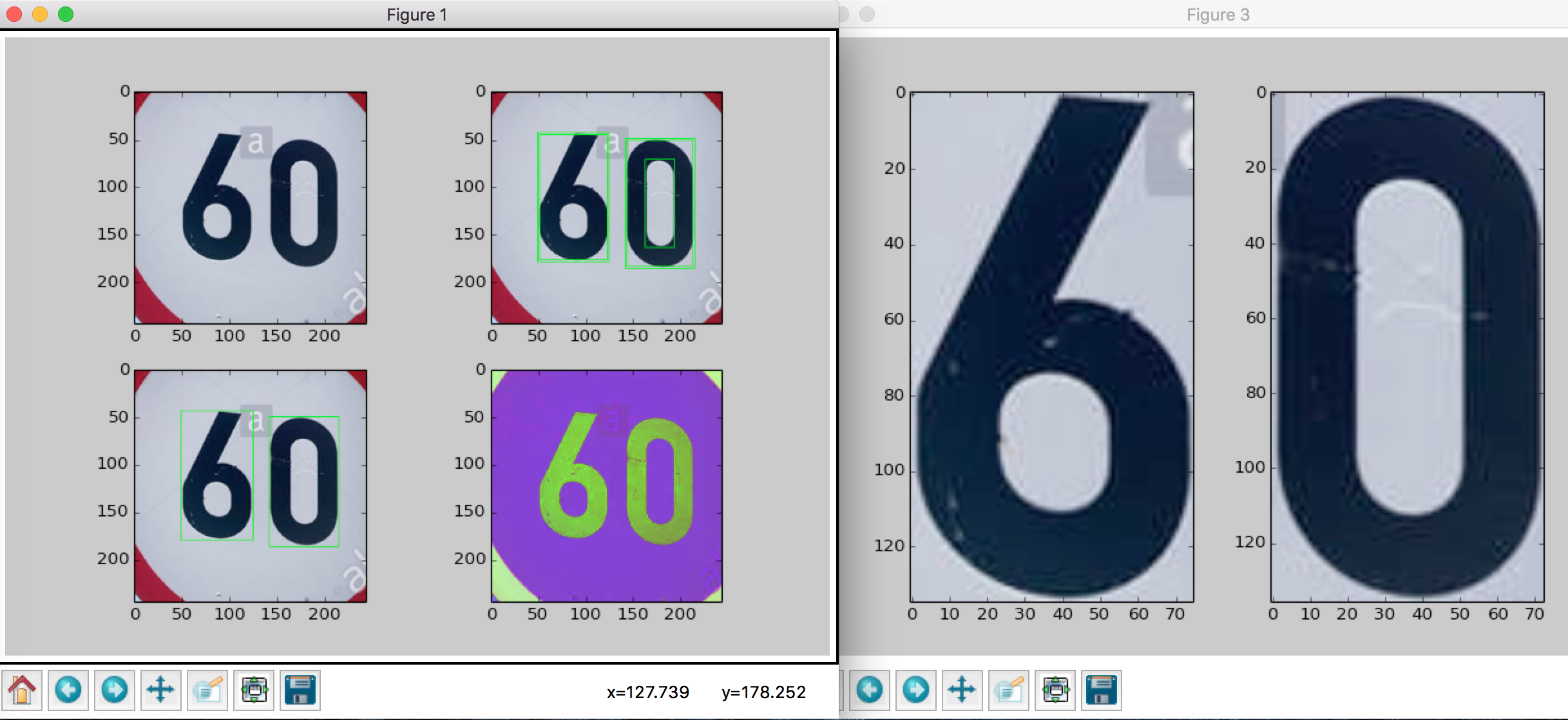
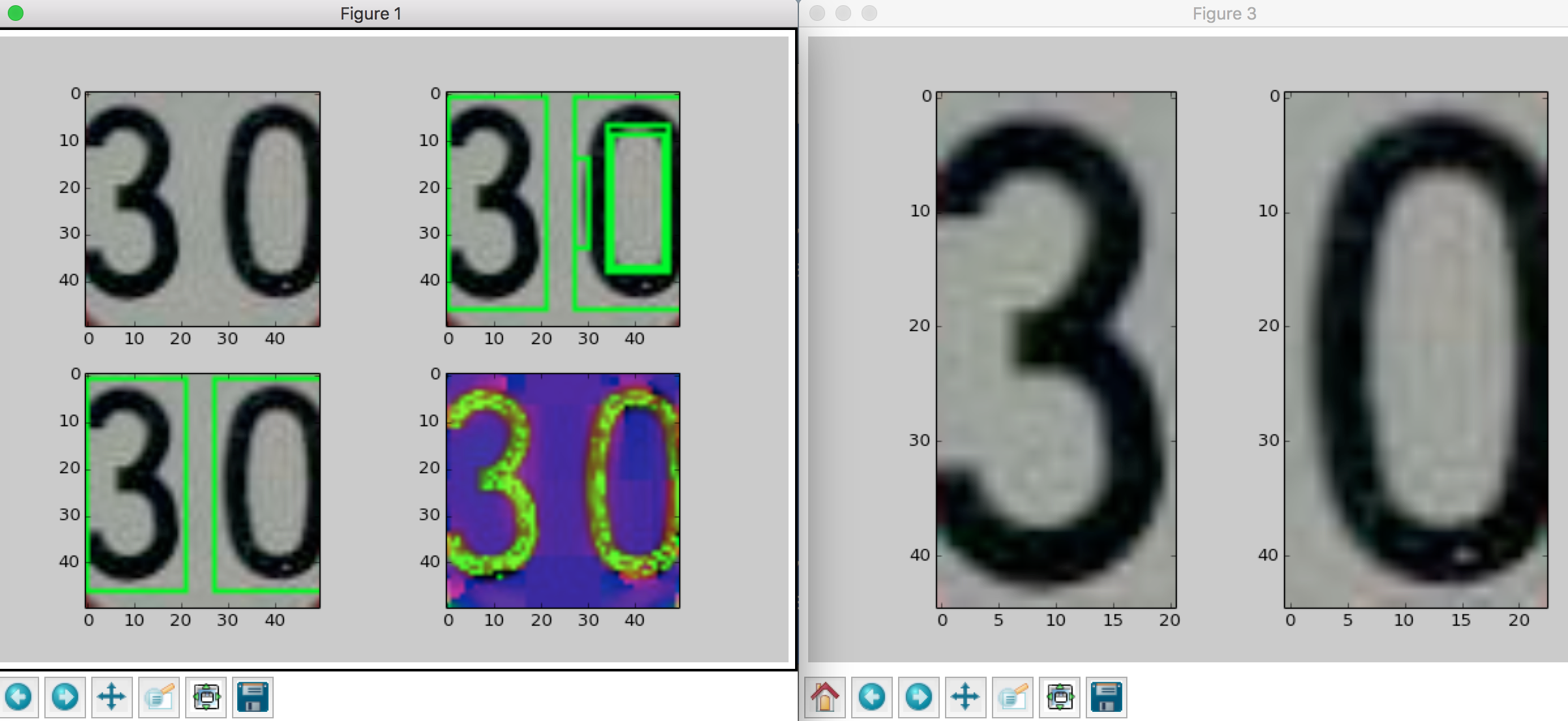
As you can see, we can extract the digits clearly. So we can apply template matching or model matching (CNN) to the images of the digits.
If you want to see the source code of the part 2 please go to GitHub Repo.